Raw data에서 특정 조건을 만족하는 레코드(행)만 추출하려고 한다.
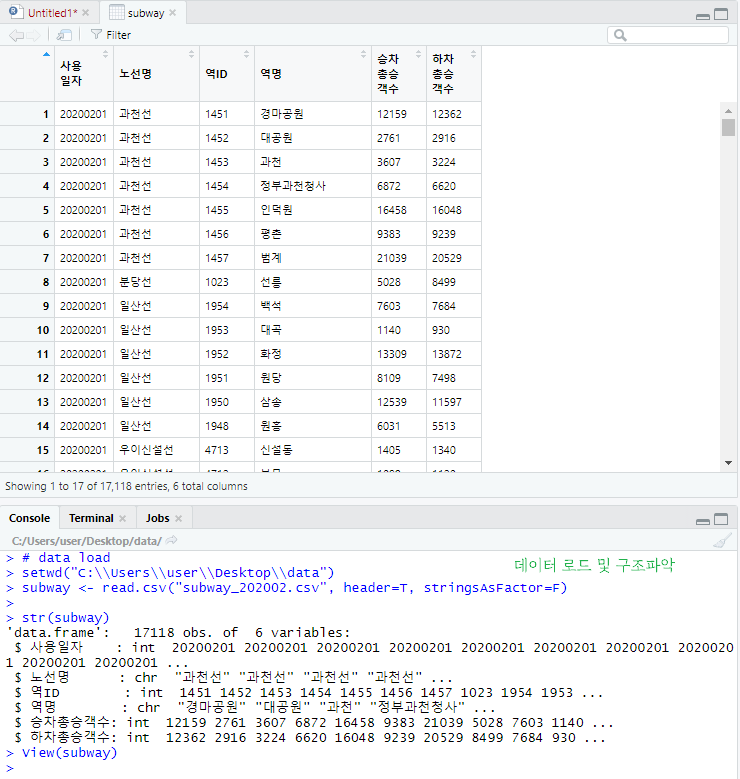
< 실습 데이터 >
서울시 2020년 2월 한 달간 역별 승하차 데이터
# data load
setwd("C:\\Users\\user\\Desktop\\data")
subway <- read.csv("subway_202002.csv", header=T, stringsAsFactor=F)
str(subway)
View(subway)
< 인덱싱 방식을 이용한 추출 >
인덱싱 방식에 데이터명[행 조건, ] 방식으로 추출하는 방법이 있다.
View(subway[subway$노선명 == '공항철도 1호선', ])
View(subway[subway$노선명 == '공항철도 1호선' & subway$사용일자 == 20200215, ])


인덱싱 방식의 추출은 간편하긴 하지만, NA값을 필터링 하지 못한다는 큰 단점이 있다.
또한 모든 행을 다 True/False 방식으로 검사하며 조건에 맞는 행을 찾아내기 때문에 데이터 양이 많아지면 속도가 현저히 느려진다.
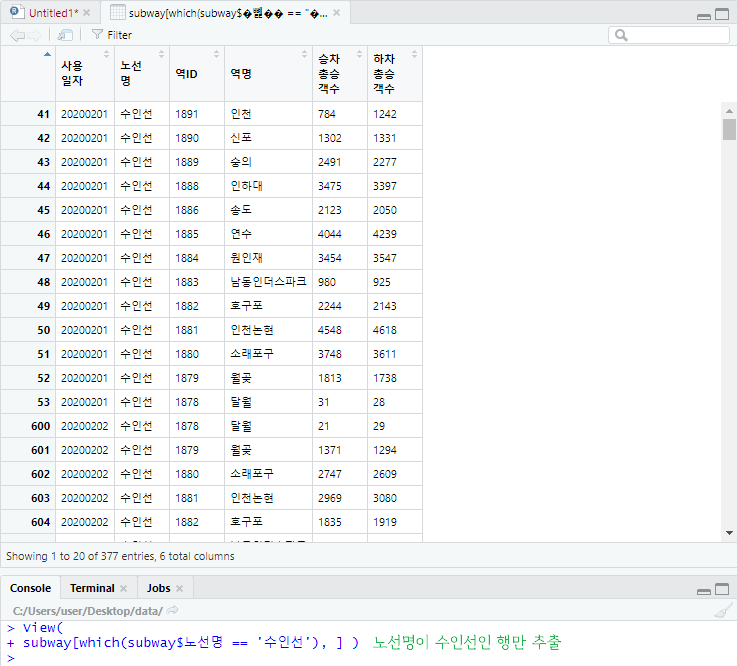
< which 함수를 이용한 추출 >
which 함수는 조건을 만족하는 위치 값만 출력한다.
인덱스방식은 모든 행을 다 True/False로 전환하여 출력하지만, which는 True인 레코드만 다루므로 인덱싱 방식보다는 빠르다.
두 개 이상의 조건을 걸어줄 때는 intersect (교집합, and 조건), Union (합집합, or 조건) 을 사용한다.
View(
subway[which(subway$노선명 == '수인선'), ] )
View(
subway[
intersect(which(subway$노선명 == '수인선'),
which(subway$사용일자 == 20200215)),
])

< dplyr 패키지를 이용한 추출 >
dplyr의 filter 함수를 이용하면 조건에 맞는 행을 추출할 수 있다.
library(dplyr) # 라이브러리 구동
subway %>%
filter(노선명 == '2호선' & 사용일자 == 20200203) %>%
View()

연속되는 사이의 범위 값을 조건으로 걸 때는 and, or 연산 대신 between을 사용할 수도 있다.
between(컬럼명, 시작구간조건, 끝구간조건)
subway %>%
filter(between(사용일자,
20200224, 20200225)
& 노선명 == '경춘선') %>%
View()

'R데이터전처리' 카테고리의 다른 글
| [R-전처리] 데이터 집계함수(dplyr group_by 최빈값과 순위 계산) (0) | 2020.03.24 |
|---|---|
| [R-전처리] 데이터 집계 함수(dplyr group_by 그룹별 요약통계) (0) | 2020.03.23 |
| [R-전처리] 데이터 집계 함수(dplyr group_by 카운트, 합계 ) (0) | 2020.03.20 |
| [R-전처리] 데이터 프레임에서 ID에 기반한 샘플링(랜덤 추출) (0) | 2020.03.19 |
| [R-전처리] 데이터 프레임에서 특정 변수 추출(dplyr select) (0) | 2020.03.17 |



