데이터 값 하나하나는 정수형, 실수형, 문자형, 논리값 등의 타입(type)을 갖는다.
그리고 한개의 값만 가지는 변수의 데이터 구조를 스칼라(scala)라고 한다.
하지만 데이터 값이 하나인 변수만 있다면 데이터 분석을 할 필요가 없다.
즉, 데이터는 늘 여러개의 값이 모여 구조를 이루는데 R에서는 데이터의 구조가 대표적으로 4가지 있다.
< 벡터 >
벡터(vector)는 모든 원소가 같은 데이터 타입을 갖는 1차원 데이터 구조이다.
원칙상 변수는 한개의 스칼라 값만 가질 수 있는데, 스칼라를 제외한 나머지 데이터 구조처럼 여러개의 값을 입력할 때는 연결함수(combine) c( ) 를 사용해 묶어준다.
# vector
x <- c(1,2,3)
x

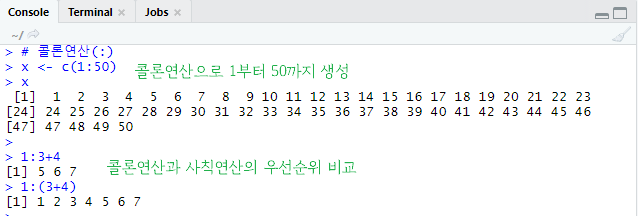
연속된 값을 만들고 싶을 때는 콜론(:) 연산자를 이용할 수 있다.
콜론 연산은 +, -, *, /와 같은 산술연산보다 우선순위이다.
수학에서 더하기 빼기보다 곱하기 나누기를 우선 계산하는 것과 같은 원리이다.
# 콜론연산(:)
x <- c(1:50)
x
1:3+4
1:(3+4)
< 행렬 >
행렬은 모든 원소가 같은 데이터 타입을 갖는 2차원 데이터 구조이다.
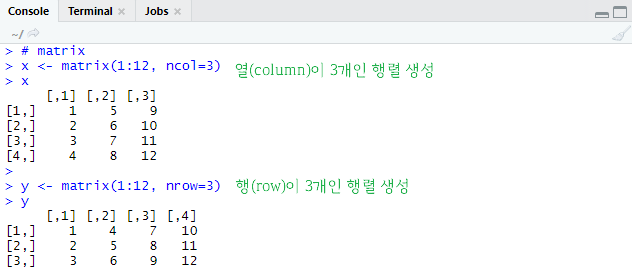
벡터의 2차원 형태이다. 2차원이므로 행(row)과 열(column)을 가지며, matrix( ) 를 이용해 생성한다.
열의 개수(cnol)나 행의 개수(nrow)를 지정해주어야 한다.
# matrix
x <- matrix(1:12, ncol=3)
x
y <- matrix(1:12, nrow=3)
y
< 리스트 >
리스트는 1차원 구조인데, 벡터와 다른 점은 두 종류 이상의 데이터 타입을 포함한다.
list ( ) 를 이용해 생성한다. 예시 코드에서 확인할 수 있듯이 서로 다른 벡터를 합쳐놓은 개념이다.
# list
x <- list("A", 1)
x
y <- list("A", "B", 2)
y
a <- list(c("A", "B", "c"), c(1,2,3))
a
b <- c("E", "F")
c <- list(b, c(1:3))
c

< 데이터 프레임 >
데이터 프레임은 리스트의 2차원 형태이다.
리스트의 속성을 그대로 가지고 있으므로, 하나의 행은 모두 다른 데이터 타입을 가질 수 있으나, 하나의 열은 모두 동일한 데이터 타입을 갖는다.
data.frame( ) 을 이용해 생성하며 열의 이름을 지정해줄 수 있다.
# data frame
x <- data.frame(name = c("Minsoo", "Mina", "Jessy"), number = c(100, 101, 102))
x
y <- list(name = c("Minsoo", "Mina", "Jessy"), number = c(100, 101, 102))
y

R이 가지고 있는 데이터 구조(벡터, 행렬, 리스트, 데이터프레임)를 모두 소개했다.
그 중에서 데이터 프레임은 가장 분석에 많이 사용되는 구조이다.
'R프로그래밍' 카테고리의 다른 글
| [R프로그래밍] 데이터 프레임 필터링, 결측치(NA와 NULL) (0) | 2020.03.10 |
|---|---|
| [R프로그래밍] 데이터 프레임 핸들링 (0) | 2020.03.09 |
| [R프로그래밍] 변수와 데이터 타입, 주석처리 (0) | 2020.03.05 |
| R Studio 설치 및 개발환경 세팅 (0) | 2020.03.04 |
| 빅데이터와 프로그래밍 (0) | 2020.03.03 |



